
在Zephyr中每个线程的堆栈大小在创建时就已经指定大小,运行过程中无法再做改变,线程运行的上下文是存放在线程的堆栈中,一旦堆栈被破坏意味着线程的执行上下文被破坏,这将导致线程执行出现不可预期的异常,Zephyr针对可能造成线程破坏的情况提供了保护,监控,预防手段。本文将介绍比较通用的一些堆栈保护技术,这些技术除了在Zephyr上出现外,其它OS也广泛的采用了这些技术。
Zephyr线程堆栈结构
Zephyr使用K_THREAD_STACK_DEFINE创建的线程堆栈,所有的线程堆栈会在内存中依次放在noinit段内。如下图所示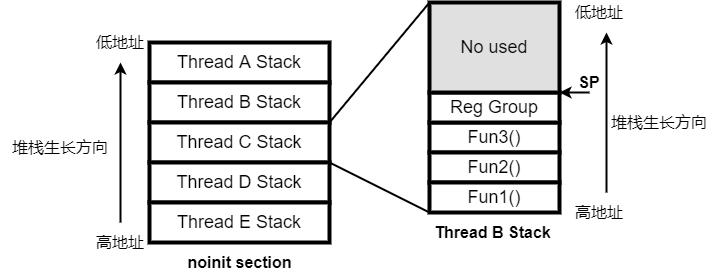
Zephyr创建了A~E五个线程相邻而放,在一个线程堆栈内函数调用会占用堆栈,诸如局部变量,传递参数等会放到堆栈内,上图函数调用关系是Fun1调用Fun2,Fuc2调用Fun3。一般情况下堆栈的生长方向是由高地址向低地址(也有特殊的体系架构是反着的),本文只讨论高向低生长的情况。 基于以上的堆栈结构,堆栈可能出现下面2个问题:
问题1. 线程中调用的函数层级过深,或者某个函数需要的堆栈很大,会导致堆栈增长超过线程分配的堆栈而写到其它线程堆栈中,例如线程C中Fun3继续调用其它函数一层层下去,堆栈会增长超过C的stack而进入到B中,把B写坏。
问题2. 函数操作局部变量发生溢出写过局部变量时可能会写坏函数堆栈,导致出错。例如Fun2的栈帧中有一个局部变量a[2],如果对a执行了memcpy超过了2,就可能写到Fun1的栈帧中。那么Fun2返回时会出现错误。
针对这两点Zephyr采用了以下技术
软件保护技术
软件保护技术通常不具有”实时”性,也就是说问题发生时不会马上报错,要等到特点的检查点检查才会报错。
1. 堆栈检查点
该技术可以查出”问题1”, 配置CONFIG_STACK_SENTINEL=y生效,原理如下图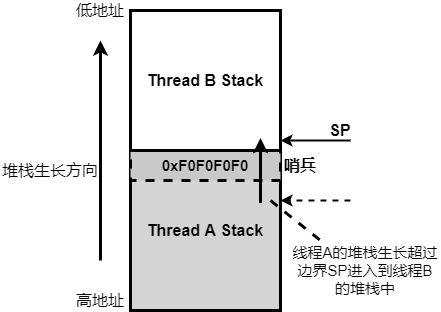
Zephyr在线程堆栈的最低地址处放一个标记0xF0F0F0F0,当堆栈溢出时会盖掉该值。Zephyr内核定期检查该值,如果发生变化就立即报错,检查点检查时机:
- 上下文切换让出CPU时,检查被切出线程的堆栈标记
- 中断发生时,检查被中断线程的堆栈标记
- 线程任务函数返回时,检查该线程的堆栈标记
- 线程调用k_yield()时,检查该线程的堆栈标记
2. 函数堆栈检查
该技术可检查”问题2”,配置CONFIG_STACK_CANARIES=y后,Zephyr对gcc编译器加入-fstack-protector-all和-mstack-protector-guard=global编译选项,使用canaries特性对函数堆栈进行检查,原理如下图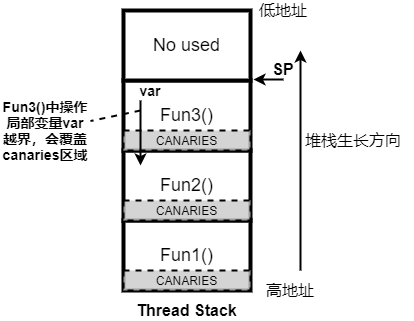
gcc会在每个函数调用前建立一个标记canaries,函数返回时检查该标记,如果标记值发生变化说明堆栈被破坏。注意该方法无法检查所有的函数栈帧破坏情况,要检查其它情况需要更重量级的工具,但并不适合使用Zephyr的小微嵌入式设备。
3.随机堆栈指针
该技术是出于安全考虑,线程使用堆栈的栈底地址进行偏移,避免非关键线程通过堆栈溢出的方式攻击关键线程,配置CONFIG_STACK_POINTER_RANDOM=y后生效,原理如下图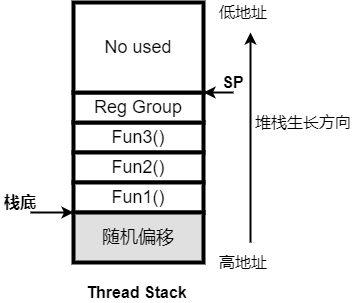
硬件保护技术
硬件保护技术具有”实时”性,一旦踩到问题硬件立即报错。在zephyr中MPU和MMU(MMU会当作MPU来用)的保护是作为通用手段。
当配置CONFIG_MPU_STACK_GUARD=y后,当前执行线程的最低地址开始减去CONFIG_ARM_MPU_REGION_MIN_ALIGN_AND_SIZE的区域将被MPU保护起来设置为不可写(保护的其它thread栈底),如果该线程出现了堆栈溢出写到该区域会触发MPU exception,如下图所示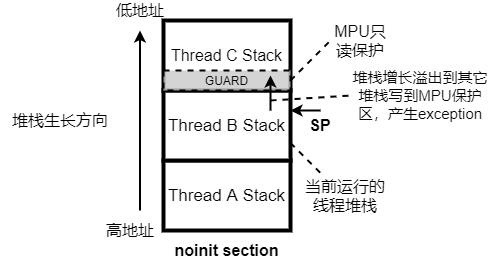
另外不同的体系架构可能会提供其它更高效方便的硬件保护方法,例如会用ARMv8-M的MSPLIM/PSPLIM寄存器可以直接保护堆栈的边沿地址,而不用使用MPU。这些内容可以根据实际使用的芯片去了解.
评估和预防
对于问题1的溢出,往往是对线程要使用的堆栈评估不足,但堆栈开大了又浪费内存。因此Zephyr提供了检查线程运行时占堆栈的方法:在创建线程时将堆栈全部写为0x0a,运行一段时间后(最好是进行全面的覆盖测试),从堆栈最低地址计算0x0a还有多少字节这就是线程未使用的堆栈,扣除这部分就可以得到线程可能使用堆栈的最大值,原理如下图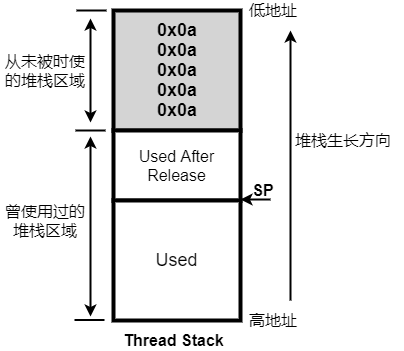
除了在运行时评估最大堆栈使用,Zephyr在配置CONFIG_STACK_USAGE=y后,编译时会加入-fstack-usage选项,gcc会在编译时计算每个函数占用的堆栈大小,通过人工或者脚本将线程全面调用关系结合函数堆栈的大小就可以计算线程将会使用堆栈的最大值。但代码中如果使用了三方库例如newlib内的函数,代码没有参与编译因此就无法评估其内部函数使用堆栈大小。当加入-fstack-usage编译完成后每个源文件都会对应的产生一个su文件,例如thread.c会产生一个thread.c.su,内容如下1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23thread.c:37:6:k_thread_foreach 0 static
thread.c:59:6:k_thread_foreach_unlocked 0 static
thread.c:77:6:k_is_in_isr 0 static
thread.c:86:6:z_thread_essential_set 0 static
thread.c:96:6:z_thread_essential_clear 0 static
thread.c:106:6:z_is_thread_essential 0 static
thread.c:112:6:z_impl_k_busy_wait 16 static
thread.c:201:5:z_impl_k_thread_name_set 0 static
thread.c:248:13:k_thread_name_get 0 static
thread.c:258:5:z_impl_k_thread_name_copy 0 static
thread.c:271:13:k_thread_state_str 0 static
thread.c:371:6:z_impl_k_thread_start 8 static
thread.c:387:13:schedule_new_thread 8 static
thread.c:493:6:z_setup_new_thread 40 static
thread.c:589:9:z_impl_k_thread_create 40 static
thread.c:677:6:z_impl_k_thread_suspend 16 static
thread.c:699:6:z_thread_single_resume 8 static
thread.c:705:6:z_impl_k_thread_resume 8 static
thread.c:737:6:z_init_static_threads 32 static
thread.c:780:6:z_init_thread_base 0 static
thread.c:443:6:z_new_thread_init 16 static
thread.c:801:20:k_thread_user_mode_enter 8 static
thread.c:851:5:z_impl_k_float_disable 0 static
字段含义:
文件名:行:列:函数名 堆栈大小 堆栈属性
主要是关注堆栈大小,更详细内容参考文末链接
参考
https://gcc.gnu.org/onlinedocs/gnat_ugn/Static-Stack-Usage-Analysis.html
https://www.ibm.com/developerworks/cn/linux/l-cn-gccstack/index.html