
作为一个多线程的操作系统Zephyr在Crash的时候你会看到Zephyr会提示如下的一些fault信息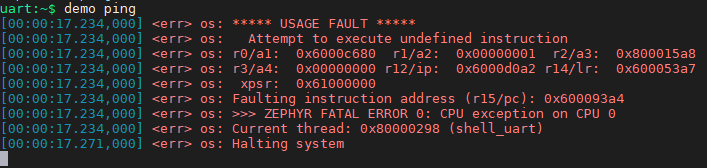
从上面的信息你可以知道出问题的thread是shell_uart,出问题的地址是0x600093a4, 通过反编译可以找到在代码里面对应到哪一行导致了Crash。但是这足够了吗? 同一个thread可能会有几个路径走到这一行代码,或者想更进一步知道是不是其它的变量操作导致了这一行代码出错。在Linux下有Coredump机制,在Process crash后会产生core file,使用gdb分析core file可以很轻松的知道crash调用backtrace,也很容易查看相关变量。但在Zephyr这种非多进程操作系统下就无计可施吗?当然不是! 大佬dcpleung在上个月为Zephyr添加了CoreDump机制,这里我们来看如何使用Zephyr的Coredump机制。
功能简介
Zephyr的Coredump机制是在上个月由https://github.com/zephyrproject-rtos/zephyr/pull/27589引入, 目前只是一个很基础的版本,提供了以下功能:
- 支持x86,x86_64,cortex-m架构的coredump
- 只支持dump单线程堆栈: 可以通过gdb查看crash线程的堆栈信息
- 支持dump data,bss,noinit 段:可以通过gdb查看全局变量
使用
1.配置
使用Coredump需要进行配置, 必选项如下1
2
3
4CONFIG_LOG=y
CONFIG_LOG_MINIMAL=y
CONFIG_DEBUG_COREDUMP=y
CONFIG_DEBUG_COREDUMP_BACKEND_LOGGING=y
注意一定要配置CONFIG_LOG_MINIMAL,这让fault的时候将数据字节送到printk,不启用该项会导致Coredump log错乱。
可选项为1
CONFIG_DEBUG_COREDUMP_MEMORY_DUMP_MIN=y
当配置了该选项后将不会dump data,bss,noinit段内存
2.产生corefile
按照上面配置后重新编译,运行程序,当触发crash时,会将寄存器的地址和内存通过送到log backend,最常用的就是我们的串口,如下图: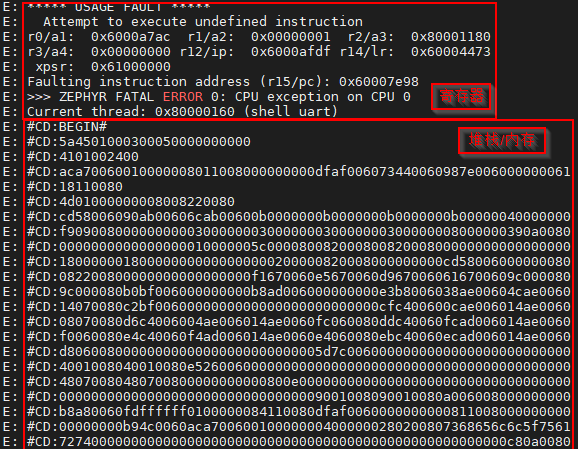
将串口中所有log全部保存为一个文件,例如叫coredump.log,使用zephyr的script将coredump.log转换为coredump.bin文件1
/mnt/e/westz/zephyrmaster/zephyr/scripts/coredump/coredump_serial_log_parser.py coredump.log coredump.bin
转换完后会提示1
2
3Input file coredump.log
Output file coredump.bin
Bytes written 8776
3.调试
由于这并不是标准的corefile文件,所以zephyr提供了一个py脚本读取该coredump.bin文件,并在py脚本中建立一个gdbserver1
/mnt/e/westz/zephyrmaster/zephyr/scripts/coredump/coredump_gdbserver.py build/zephyr/zephyr.elf coredump.bin
此时,使用gdb对zephyr.elf进行调试1
/mnt/e/westz/zephyr-sdk-0.11.3/arm-zephyr-eabi/bin/arm-zephyr-eabi-gdb-no-py build/zephyr/zephyr.elf
执行下面命令链接gdbserver1
target remote 127.0.0.1:1234
连接后按照正常的gdb操作,执行bt就可以看到crash的位置和backtrace了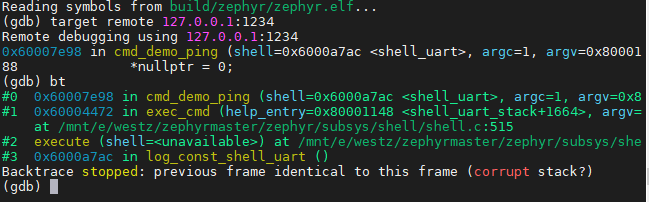
例如上图可以看到是操作*nullptr = 0引起的crash,那么我们可以再看下nullptr是什么值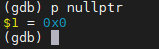
这里看到nullptr是0地址,在rt1052上对该地址进行写操作是非法的,因此会crash。
由于我们没有配置CONFIG_DEBUG_COREDUMP_MEMORY_DUMP_MIN,因此也可以通过gdb查看全局变量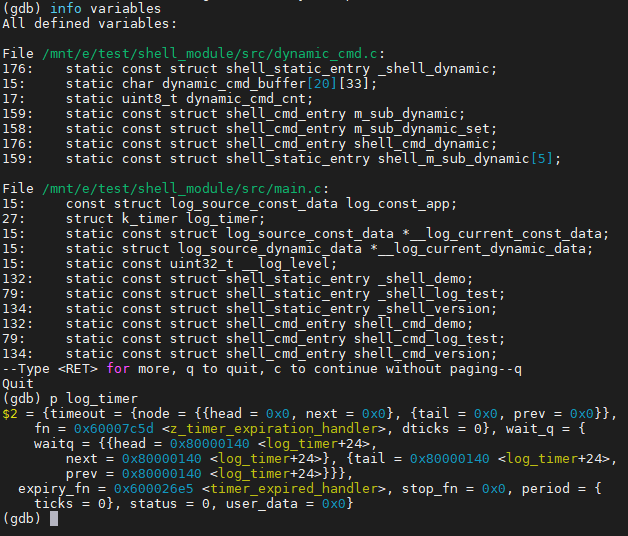
原理简介
Zephyr和Linux不太一样,大多数时候可能没有FS,因此不太可能直接生成corefile, 因此将寄存器信息和内存数据输出到log终端,然后再转化为特定的coredump进行分析。
在Zephyr crash发生时会触发z_irq_spurious,以cortex为例:
z_irq_spurious->z_arm_fatal_error1
2
3
4
5
6
7
8void z_arm_fatal_error(unsigned int reason, const z_arch_esf_t *esf)
{
if (esf != NULL) {
esf_dump(esf); //这里dump出寄存器信息
}
z_fatal_error(reason, esf);
}
1 | void z_fatal_error(unsigned int reason, const z_arch_esf_t *esf) |
1 | void z_coredump(unsigned int reason, const z_arch_esf_t *esf, |
调试时通过脚本coredump_serial_log_parser.py将文本格式的Coredump.log转化为二进制格式的Coredump.bin。然后通过coredump_gdbserver.py读取分别coredump.bin,并在脚本中建立gdbserver,提供标准的gdb remote接口。之后就可以gdb进行coredump分析了,脚本具体不在分析,大家可以参考scripts/coredump/下的内容。
目前Zephyr已经有了这个Coredump框架,未来加入多线程堆栈dump和heap dump可以期待,基本可以达到Linux上coredump的水平。从这种形式上来看Zephyr被叫做是一个小型嵌入式设备的Linux,不仅仅在代码架构上,也体现在调试工具上。
最后需要注意的是Zephyr的Coredump和Linux下的Coredump文件结构并不一样,因此是无法直接使用gdb进行调试的,关于文件结构可以参考文末链接。这里也附上我调试用coredump文件,方便大家尝鲜Coredump.7z。
参考
https://docs.zephyrproject.org/latest/guides/debugging/coredump.html